
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- latent diffusion model
- Textual Inversion
- Diffusion
- ViCo
- Deep Learning
- Ai
- 딥러닝
- diffusion model
- latent diffusion
- dreambooth
- Computer Vision
- CVPR
- generative model
- subject driven
- subject-driven
- Stable Diffusion
- model
- Today
- Total
kkm0476
[논문리뷰] High-Resolution Image Synthesis with Latent Diffusion Models 본문
[논문리뷰] High-Resolution Image Synthesis with Latent Diffusion Models
kkm0476 2024. 3. 18. 22:16High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR 2022 [paper] [github]
Contents
1. Introduction
2. Method
3. Experiments
4. Limitations
5. Summary
1. Introduction
이미지 합성(image synthesis)은 최근 많은 발전을 이룬 컴퓨터 비전 분야이다. 그럼에도 아직 여러 문제점들이 존재하는데, 그중 하나는 computing cost이다. 특히 고해상도 이미지를 합성하는 high-resolution image synthesis는 수십억 개의 파라미터를 갖는 Autoregressive model을 필요로 한다. 최근에는 diffusion model을 활용한 연구가 진행되고 있다. diffusion model은 class conditional synthesis, high resolution synthesis 등의 분야에서 SOTA (State-Of-The-Art)를 달성했다. Diffusion model은 기존 AR 모델의 장점을 가지면서도 적은 수의 파라미터로 데이터를 표현할 수 있다.
그럼에도 diffusion model은 여전히 높은 computing cost를 필요로 한다. Diffusion model과 같은 likelihood-based model의 특징은 데이터의 imperceptible한 특징을 표현하는데 많은 리소스가 낭비된다는 것이다. DDPM에서 variational objective를 reweight 한 loss function을 새롭게 정의함으로써 문제를 일부 해결하였다. 그렇지만 diffusion model의 training과 evaluation 과정에서 수 차례의 step 동안 고해상도의 이미지를 계산해야 하기 때문에 여전히 많은 computing cost를 요구한다.
Diffusion model의 학습 단계는 데이터에서 의미 없는 부분을 제거하는 perceptual compression과 모델이 데이터의 특징을 학습하는 semantic compression로 구성된다. 연구진들은 data space와 perceptually equvalent하면서도 계산하기 좋은, lower-dimensional latent space를 찾는 것을 목표로 하고 연구를 진행하였다. 연구진들은 학습을 두 단계로 구성했다. 먼저, data space와 perceptually equivalent 하면서 lower-dimensional인 latent space를 찾는 autoencoder를 학습한다. 얻어낸 latent space에서 diffusion model을 학습하며, 연구진들은 이를 LDM (Latent Diffusion Model)이라고 명명했다. LDM은 여러 장점을 가지고 있다. 한번 학습한 autoencoder는 다른 diffusion model의 학습에도 활용할 수 있다. lower-dimensional data space에서 training와 inference가 진행되기 때문에 기존의 diffusion model에 비해 걸리는 시간이 짧다. 최신 논문들의 base로 자주 사용되는 Stable Diffusion도 LDM을 기반으로 구현되었다.
2. Method
Perceptual image compression 과정에서 사용되는 autoencoder는 perceptual loss와 patch based adversarial objective를 조합하여 학습된다. 이미지 $x \in \mathbb{R}^{H \times W \times 3}$가 주어지면 인코더 $\mathcal{E}$는 주어진 이미지 $x$를 latent representation $z = \mathcal{E} \left( x \right) \in \mathbb{R}^{h \times w \times c} $로 변환한다. 반대로 디코더 $\mathcal{D}$는 latent space로부터 이미지 $\tilde{x}=\mathcal{D}(z)=\mathcal{D}(\mathcal{E}(x))$를 재구성한다. Image space로부터 latent space로 압축되는 비율은 downsampling factor $f=H/h=W/w$로 나타낸다. LDM은 기존 연구들에 비해 상대적으로 적은 압축률을 사용하여 이미지의 디테일을 보존할 수 있다. Autoencoder의 전체 objective function은 다음과 같다.$$
L_{\text {Autoencoder }}=\min _{\mathcal{E}, \mathcal{D}} \max _\psi\left(L_{r e c}(x, \mathcal{D}(\mathcal{E}(x)))-L_{a d v}(\mathcal{D}(\mathcal{E}(x)))+\log D_\psi(x)+L_{r e g}(x ; \mathcal{E}, \mathcal{D})\right)$$
Diffusion model은 표준 정규분포 $\mathcal{N}(0,1)$로부터 샘플링한 noise를 수 차례의 step 동안 denoising 하는 과정을 반복하여 데이터 분포 $p(x)$를 학습한다. 이는 길이 $T$의 마르코프 체인의 역과정을 학습하는 것으로 볼 수 있다. 학습 과정에서는 UNet 모델 $\epsilon(x_t, t)$이 입력 $x_t$로부터 noise를 예측하도록 학습된다. Diffusion model의 objective function은 다음과 같다.$$
L_{D M}=\mathbb{E}_{x, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_\theta\left(x_t, t\right)\right\|_2^2\right]
$$
LDM은 미리 학습한 autoencoder를 이용해 latent space에서 위 과정을 진행한다. 이는 모델이 데이터의 중요하고 의미 있는 정보에 집중하게 하며, lower-dimensional space에서 학습함으로써 낮은 computing cost 만을 요구하도록 한다.
LDM의 objective function은 다음과 같다. $$
L_{LDM}:=\mathbb{E}_{ \mathcal{E} (x), \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t\right)\right\|_2^2\right]
$$ $z_t$는 step $t$에서의 latent representation이고, denoising process의 결과 $z_0$은 디코더 $\mathcal{D}$에 통과시켜 이미지로 디코딩할 수 있다.
LDM은 기존 모델들과 마찬가지로 conditional image synthesis이 가능하다. 조건부 모델 $\epsilon_\theta (z_t, t, y)$을 사용하여 LDM으로 조건부 분포 $p(z \vert y)$를 모델링할 수 있다. 입력 $y$는 text prompt, image 등의 다양한 형태로, semantic map, image-to-image 등의 task에 따라 달라질 수 있다. LDM은 conditional image synthesis를 위해 Unet 모델에 cross attention 구조를 결합한다. 다양한 task에 사용할 수 있도록 $y$를 $\tau_\theta (y) \in \mathbb{R}^{M \times d_\tau}$로 맵핑하는 domain-specific 인코더 $\tau_\theta$를 사용한다. 변환된 입력은 cross attention layer를 통해 Unet의 레이어에 합쳐진다. cross attention layer는 아래 식으로 표현할 수 있다.
$$ \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d}}\right) \cdot V$$$$Q=W_Q^{(i)} \cdot \varphi_i\left(z_t\right), K=W_K^{(i)} \cdot \tau_\theta(y), V=W_V^{(i)} \cdot \tau_\theta(y)$$$ \varphi_i\left(z_t\right) \in \mathcal{R}^{N \times d_{\epsilon}^i}$는 UNet의 flatten된 중간 레이어 값이고, $W_V^{(i)} \in \mathbb{R}^{d \times d_\epsilon^i}, W_Q^{(i)} \in \mathbb{R}^{d \times d_\tau} , W_K^{(i)} \in \mathbb{R}^{d \times d_\tau}$는 학습 가능한 행렬이다. 모델의 전체 구조는 다음과 같다.

$\tau_\theta$와 $\epsilon_\theta$ 둘 다 image-conditiong pair을 기반으로 다음 objective를 통해 학습시킨다. $$L_{LDM}:=\mathbb{E}_{ \mathcal{E} (x), y, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, \tau_\theta (y) \right)\right\|_2^2\right]$$
3. Experiments

위 표는 downsampling factor $f$에 따른 LDM의 성능을 분석한 결과이다.
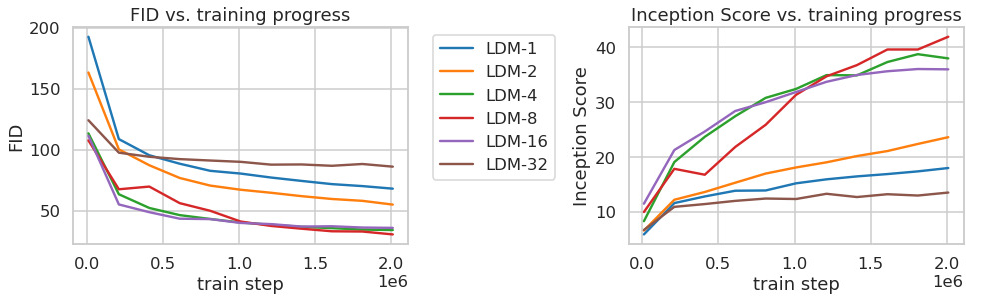
위 그래프는 class-conditional model을 ImageNet 데이터셋으로 2M steps 학습하는 동안 모델의 성능 변화를 나타낸다. 그래프로부터 다음과 같은 사실을 알 수 있다. 1. 작은 downsampling factor ($f=1, 2$)는 학습을 느리게 만든다. 2. 너무 큰 downsampling factor ($f=32$)는 특정 스텝 이후로 학습이 정체되게 만든다. 이러한 결과는 다음과 같이 이해할 수 있다. 1. first stage에서 perceptual compression이 거의 진행되지 않았다. 2. first stage에서 compression이 과하게 진행되어 정보가 손실되었다. $f=4, 8, 16$의 경우에 효율성과 품질 사이에서 적절한 균형을 유지하는 것을 알 수 있다.

위 그래프는 class-conditional model을 ImageNet 데이터셋으로 2M steps 학습하는 동안 모델의 성능 변화를 나타낸다. 그래프로부터 다음과 같은 사실을 알 수 있다. 1. 작은 downsampling factor ($f=1, 2$)는 학습을 느리게 만든다. 2. 너무 큰 downsampling factor ($f=32$)는 특정 스텝 이후로 학습이 정체되게 만든다. 이러한 결과는 다음과 같이 이해할 수 있다. 1. first stage에서 perceptual compression이 거의 진행되지 않았다. 2. first stage에서 compression이 과하게 진행되어 정보가 손실되었다. $f=4, 8, 16$의 경우에 효율성과 품질 사이에서 적절한 균형을 유지하는 것을 알 수 있다.
위 그래프는 각각 CelebA-HQ와 ImageNet 데이터셋에서 학습한 모델의 성능을 비교한 결과를 나타낸다. 각 모델은 여러 denoising step에서 학습되었다. $f=4, 8$의 경우에 가장 좋은 성능을 보여주는 것을 확인할 수 있다. 특히 latent space를 거치지 않은 pixel-based model인 $LDM-1$에 비해 낮은 FID를 달성하면서도 훨씬 빠른 샘플링 속도를 보인다.
아래 표는 $256^2$ 이미지 데이터셋에서 훈련한 unconditional model의 결과이다.

CelebA-HQ 데이터셋에서 FID에서 SOTA를 달성했으며, 다른 데이터셋에서도 기존 모델보다 훨씬 적은 computing cost만으로 밀리지 비슷한 성능을 보인다. GAN based 모델에 비해 likelihood based 모델인 LDM이 높은 precision과 recall을 보이는 것도 확인할 수 있다.
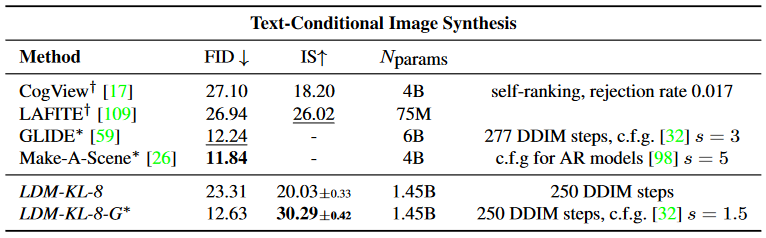
LDM은 cross attention layer를 통해 다양한 task에 대한 conditional image synthesis를 할 수 있다. BERT-tokenizer와 transformer를 통해 text prompt에 대한 인코더 $\tau_\theta$를 구현해 text-to-image task에 사용할 수 있다. 아래에서 LAION 데이터셋과 MS-COCO 데이터셋에서 학습한 text-to-image 모델들의 결과를 확인할 수 있다.

이 밖에도 Layout-to-image, class conditioning, image-to-image 등의 다양한 분야에서 훌륭한 성능을 보인다.
LDM은 저해상도의 이미지를 conditioning하여 고해상도 이미지 합성을 학습할 수 있다. 아래 그림은 ImageNet-Val, LDM-SR의 64$\rightarrow$256 upscaling 샘플들이다.

아래 표는 ImageNet-Val에서의 64$\rightarrow $256 upscaling 결과이다.

기존 방법론에 비해 훨씬 적은 파라미터를 사용하면서도 괜찮은 성능을 보여준다.
Inpainting은 이미지의 마스킹된 부분을 새로 채우는 작업이다. 미완성 이미지의 비어있는 부분을 채울 수도 있고 마스킹된 부분의 물체를 다른 물체로 대체할 수도 있다. 아래 그림은 object removal을 시도한 결과이다.

아래 표는 기존 방법론과의 성능 비교이다.

아래 설문 결과로부터 기존 방법론에 비해 super-resolution synthesis와 inpainting에서 좋은 평가를 받았음을 알 수 있다.

4. Limitations
본 연구에서 기존의 pixel-based 방법론에 비해 계산 요구량을 크게 줄였지만, sequential한 샘플링 과정에 의해 여전히 GANs에 비해 느리다. 또한, 높은 정확성을 요구하는 작업에 대해 LDM을 사용하는 것은 한 번 생각해 보아야 한다. $f=4$인 경우에 autoencoder에 의한 이미지 품질의 손실은 매우 적지만, pixel space에서 높은 정확도를 요구하는 작업의 경우에는 이에 의한 reconstruction 과정이 bottleneck으로 작용할 수 있다.
5. Summary
연구진들은 품질의 손실 없이 학습과 샘플링 과정을 효율적으로 개선하는 Latent Diffusion Model을 제시하였다. 기존에 Diffusion Model의 효율 개선을 위한 다양한 연구가 진행되었음에도 불구하고, pixel space에서 여러 단계에 걸쳐 진행되는 학습 및 샘플링 과정은 여전히 많은 computing cos를 요구한다. 본 논문에서는 pixel sapce에서 perceptually equivalent 하면서도 lower-dimensional 한 latent space로 변환하는 autoencoder를 학습하여 정보의 손실 없이 저차원에서 효율적인 학습 및 샘플링이 가능하도록 개선하였다. 또한 UNet backbone에 cross-attention을 도입하여 다양한 task에 대해 conditional image synthesis가 가능하도록 하였다. 다만 sequential하게 진행되는 샘플링 과정 때문에 여전히 GANs 모델들에 비해 느리고, super-resolution task에서 autoencoder가 bottleneck으로 작용할 수 있다.



